Reinforcement learning
This lab is an Implementation of the cart pole problem which is a Markov decision problem. The cart moves to prevent the standing pole from falling. Let’s describe the STAR of this problem: State: (coord of cart, speed of cart, angular coord of pole, angular velocity of pole) Transition: mvt of cart and pole. Action: moving the cart left or right. Reward: virtual cône of validity (+1 when it stays 0 when it falls out)
Usually, in the same way you work with Deep Learning, you never start a reinforcement learning model from scratch, it’s in order to understand what’s inside that we do so here.
We use gym module from openAI to display our training: https://github.com/openai/gym/blob/master/gym/envs/classic_control/cartpole.py we can see it describes our problem (STAR, episodes etc)
Q network our Q network uses linear layers as we deal with small vectors and has one output per action (ie the last dense has n_actions neurons) The output gives for each state the score of each action. our Q networks outputs an array as this one: [ 0.3241, -0.1825], [ 0.2795, -0.1629], [ 0.3021, -0.1491], [ 0.2498, -0.2195], [ 0.3348, -0.2267], [ 0.3443, -0.2204], [ 0.3194, -0.2692], [ 0.3428, -0.1314], [ 0.3058, -0.2187], [ 0.2643, -0.1601]] Each line represents a state and the column two elements values of the two actions, we chose the max for each line. Here we chose action 0 which represents left in every state.
Doer: does the actions according to the values the Q network provides. As an example, this is a basic process of the doer: qValues : [-0.2774849534034729, -0.473802387714386] action : 0 Action 0 is done because of the qvalues maximum.
Experience Replay: defines transitions between states to update the Q network in training according to the relevance of the states. For example, you can chose to tweak hyperparameters such as batchsize and weightBatches in order to define how the transitions weigh on your model (removing transitions that yield the least amount of loss for example) Learner: it’s the training process, linking the Experience Replay to the Q network By copying and freezing the copy of the network, we can evaluate the learning progress. We use SARSA or Q learning in order to define the target for the model at every state. The frozen copy always catches up with the network in order to continue training by sharing weights .
Training loop Dataset changes over time so the loss is always changing, Score is also moving up and down as the epochs pass but less randomly than the loss, we can display it as results.
First result with width 128 and q-learning
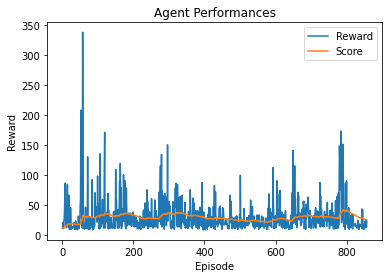
We can see that some episodes gave much reward and therefore increased the the score in a significant way
Changing the capacity of our network: width (128 ⇒ 256) We know that the way we handle data influences the output (sort transition= false /true) change the training as your own old data is considered as off policy (we know that q learning is better than SARSA for off policy so we’ll stick to this)
Remarks about the training and outputs: -Some walls exist in the training as the score needs many episodes to go above some values, there’s one around 20. -Results depend on the seed so it’s hard to reproduce outputs
Let’s look at the transitions of an episode:
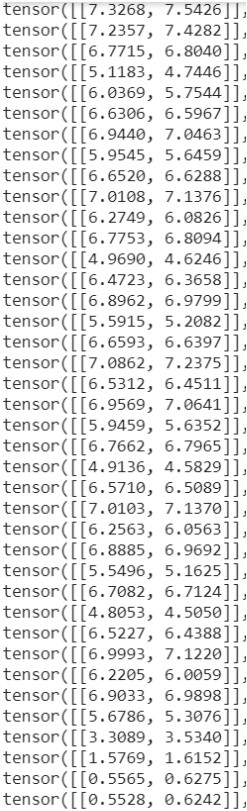
Here, we have few information about what’s going on between 5 and 0 Iteration 2900 | floss : 1.29978 | Score: 25.418 | eps: 0.1
Gamma was 0.9 before, let’s change this value as we know it influences drastically the learning by changing the plateau at which the values function converge and therefore a gamma close to 1 considers more old rewards than for a small value of gamma, it’s called a discount rate and tackles the credit assignment problem of reinforcement learning.
So let’s try gamma 0.7 ⇒ values plateau around 30
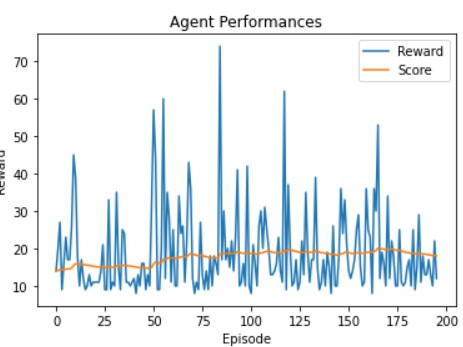
Here, we can see that the first “wall” can not be passed because the newest rewards are way more important than the old one (0,7)^n.
gamma 0.8 values plateau around 20:
last Iteration 3600 | floss : 0.52268 | Score: 18.369 | eps: 0.1
This is a great run I did but I don’t remember the exact config, all I know is that I used a width of 256 so that explains the good results:
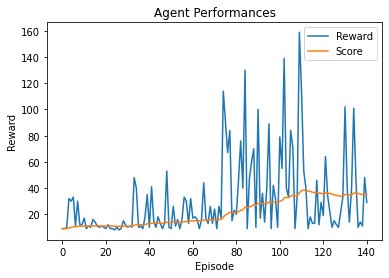
The last run I did was using -1 as error and using 4 experience replay batches with/without transition sorting and weighted batches ( see the training loop function of the ipynb file). Here we reach another issue: the agent leaves the room creating a wall around 50 (see the video that shows the issue).
//unfortunately I cannot retrieve this video as I wanted too because I accidentaly reruned with another seed and lost it:

This must require much bigger buffer sizes and batches to be passed and I could not figure out how to pass the wall. Below, I printed the last iterations that show the 50 score wall (I could not go much longer because of the buffer sizes and batches, the training was way longer than on previous attempts). Iteration 4200 | floss : 0.01924 | Score: 43.135 | eps: 0.1 Iteration 4300 | floss : 0.01319 | Score: 42.333 | eps: 0.1 Iteration 4400 | floss : 0.01118 | Score: 42.333 | eps: 0.1 Iteration 4500 | floss : 0.01605 | Score: 45.075 | eps: 0.1 Iteration 4600 | floss : 0.01935 | Score: 44.415 | eps: 0.1 Iteration 4700 | floss : 0.01261 | Score: 44.887 | eps: 0.1 Iteration 4800 | floss : 0.0132 | Score: 47.029 | eps: 0.1 Iteration 4900 | floss : 0.01434 | Score: 46.68 | eps: 0.1 Iteration 5000 | floss : 0.01321 | Score: 48.326 | eps: 0.1 Iteration 5100 | floss : 0.01421 | Score: 49.459 | eps: 0.1 Iteration 5200 | floss : 0.01264 | Score: 47.678 | eps: 0.1 Iteration 5300 | floss : 0.01266 | Score: 44.781 | eps: 0.1 Iteration 5400 | floss : 0.01787 | Score: 43.179 | eps: 0.1 Iteration 5500 | floss : 0.01717 | Score: 43.355 | eps: 0.1 Iteration 5600 | floss : 0.01813 | Score: 43.14
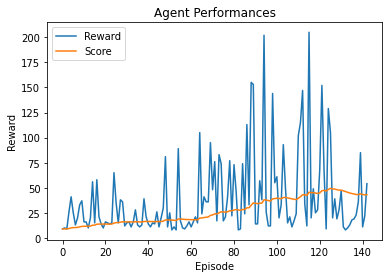
see the ipynb file for better quality of the graph
This last loop gave quite interesting results as it could show the 50 wall and I had a long run episode to analyse (see the display of the transition cell on the ipynb). In this episode, we can explain the influence of the gamma value: we see that the Q values are all below 1 so the agent has few reasons to take one decision or the other and the difference between both is very small, it can be explained by the birthdate of the transition: 99 as the gamma value diminishes the importance of old transitions as we saw previously.
We can conclude that reinforcement learning is somehow easy to understand in a general way but the implementation and hyperparameters tuning are still quite complex (the influence of gamma over the target value and how it influences training was hard to get at the beginning but displaying an interesting episode such as the last one was helpful.)