Generalities on Recurrent Neural Networks and image captioning application
The main goal of RNN is to deal with sequential data as it can easily handle long-term dependencies and order. Vanilla RNNs use backpropagation but suffer from vanishing gradients by multiplying over and over by a same factor:
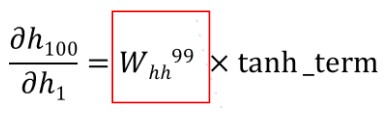
Therefore, we use LSTM to manage the vanishing gradient issue by changing the cell architecture. RNN are widely used for text,image generation, and text translation but also image captioning which is what interests us in this lab . Other applications are also possible such as hand gestures recognition. image captioning which deals with important aspects of RNN such as attention, as it must implement convolutional feature extraction on the image.
In this lab, we implement an image captioning model based on the following pipeline:
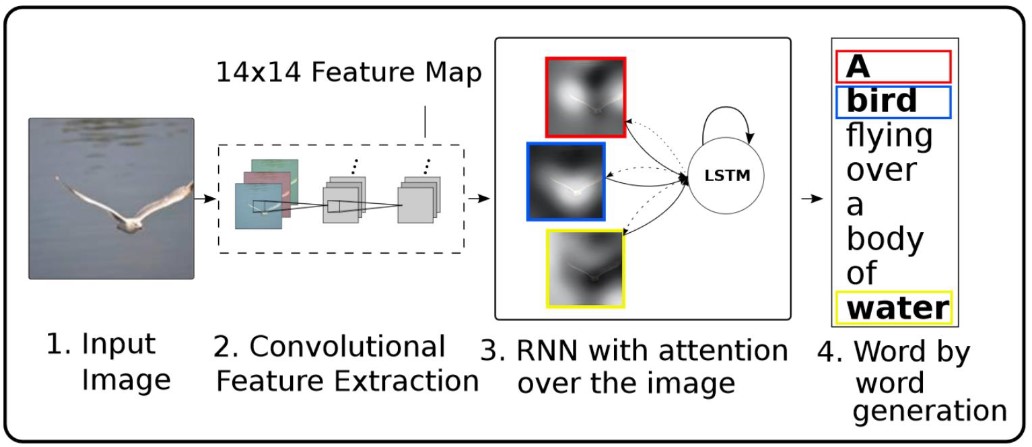
We take an image as input and extract features using CNN (Inception), then we feed those features to a RNN (a LSTM) in order to generate captions as a word by word generation. We used the COCO 2014 dataset for training.
Dataset description and pre-processing : goal here is to understand the structure of the dataset and then pre-process the data so that the model can take it as a standardized input. Encoder: we use Inception pre trained with ImageNet as a CNN encoder (because we’re dealing with images as input and need to extract features from it). Decoder: LSTM and Encoder-Decoder model linking the CNN model to the LSTM Training: we train the model on the COCO 2014 dataset but because of the running time, we could not extract features from the dataset using our CNN so we used pickle to load pre-extracted features to work on. Inference: We use our model to see how it generalizes on the test set. Here is the github link to my ipynb file explaining and running the lab: https://github.com/Foglia-m/IA/blob/main/RNN_icap_lab
We can say that the global outline of RNN implementation is very close to simple machine learning (or even deep learning) tasks such as classification and regression using FFNN and CNN. Here the tricky part is to correctly understand how the input works as it’s sequential data and how the different models (coder and encoder) are merged into a unified model called the coder-encoder which performs the whole process. Also, sequential data such as words requires to deal with vocabularies (for padding and also mapping purposes) which is of course linked to the tricky aspect of the input.
What is so interesting about RNNs? RNNs always have some kind of magical aspect because of the data generation, whether it is text or images, but it showcases all its potential with video games AI applications for complex games such as RTS (Starcraft, AOE) by working along with reinforcement learning such as Q learning. Here, the attention is at the core of the problem since the AI has to deal with many complex and different data so instead of basic RNN, attention based models called transformers are used here (they’re also used in Natural Language Processing as they provide much better results).
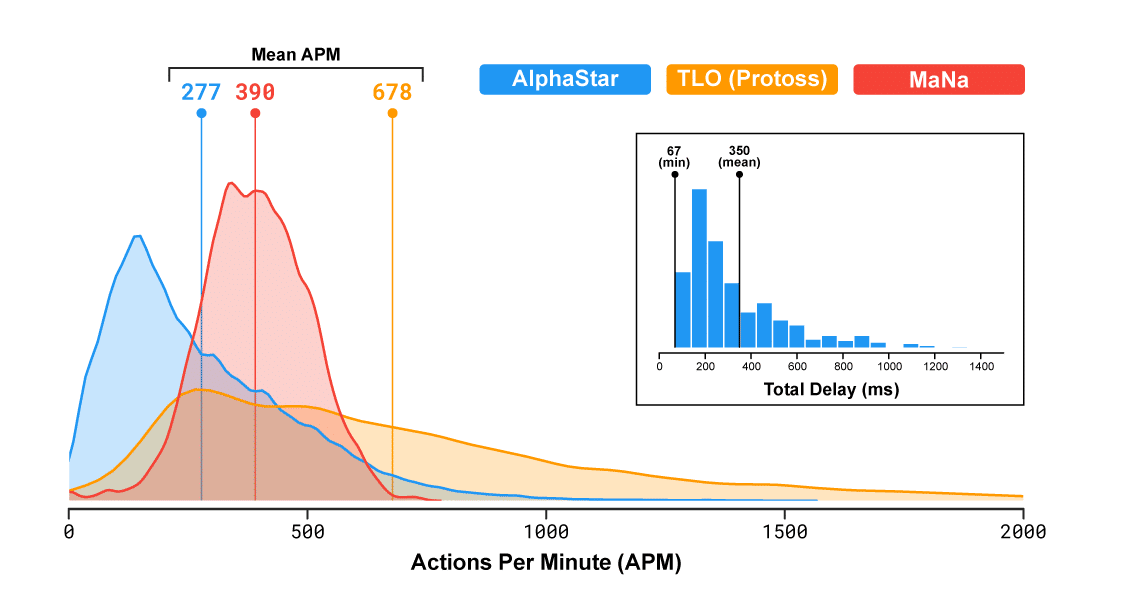
The idea that mostly intrigues me is to beat a player only using learned strategy and also spontaneous tactics instead of using a huge amount of APM (action per minute) which makes it a boring fast-computer asset. We know that the best pro gamers have a mean of more than 400 APM. Here we can see what APM are the current best AI using, we can see that it’s quite fitting the standards pro gaming APM.